ARM社は、今年2月に発表した(関連記事)64bitプロセッサ「Cortex-A72」などの詳細情報を公開した。


Cortex-A72は、スマートフォンの電力消費の範囲内でA15の3.5倍の性能がある。シングルスレッド性能を重視しており、高い電力効率を持つ
今年のフラグシップスマホに採用されている
第1世代64bitコア「Cortex-A57」の性能をさらにアップ
Cortex-A72は、Cortex-A57に続く、第2世代の64bitプロセッサである。ARMv8と呼ばれるアーキテクチャを持ち、従来の32bitと互換性のあるAArch32と、新たに定義された64bit命令を実行するAArch64を持ち、モードを切り替えることで2種類の命令セットを切り替えることが可能だ。
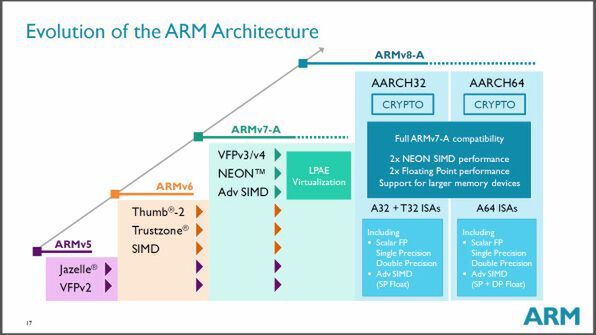
ARMv8は、32bitモードであるAArch32と64bitモードAArch64があり、それぞれで違う命令セットを持つ。なおAArch32は、32bitアーテキクチャのARMv7と完全互換
ARMによればCortex-A72は、今年のフラグシップ機で採用されているCortex-A57(Snapdragon 810やExynos 7などで用いられている)と比較して、1.16~1.5倍の性能があるという。
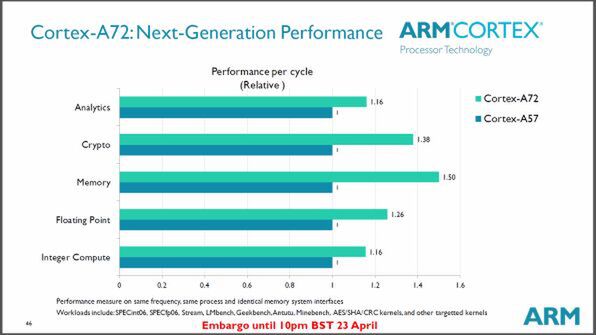
前世代のCortex-A57と比較してクロックサイクルあたり1.16~1.5倍の性能を持つ
Cortex-A72の製造は16nm(または14nm)プロセスを想定して設計されており、28nmで製造されているCortex-A15と比較すると最大で3.5倍の性能があるという。
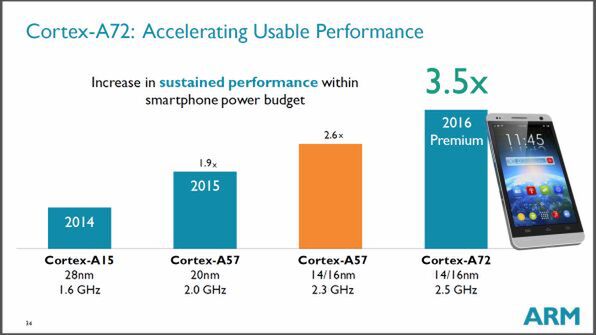
スマートフォンの電力範囲では、現行のCortex-A15の3.5倍の性能がある
また、Cortex-A15と同じ28nmで製造し、同じ負荷とした場合、Cortex-A72はCortex-A15のほぼ半分の消費電力で動作し、16nmで製造した場合には75%も電力を削減することができるという。
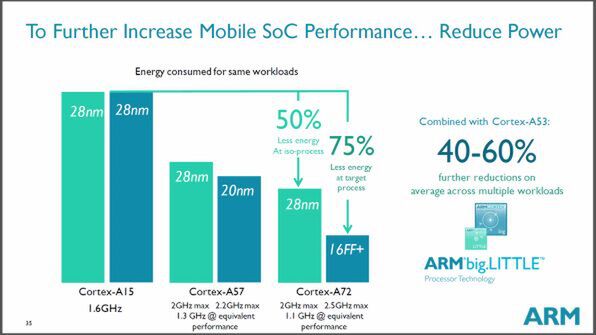
現行のCortex-A15と同じ28nmで製造すれば、A72は約半分の消費電力で動作し、最新の16nmプロセスでの製造では、25%の電力で動作できる
なおARM社は、プロセッサの基本設計を行なうだけで、実際の製品は、半導体メーカーが、自社の製造プロセスなどに最適化する作業を行い、周辺回路と組み合わせて設計を行ったうえでSoCとして製造する。
スマートフォンなどのセットメーカーは、これを採用して製品を開発する。このため、Cortex-A72を採用したSoCが登場するのは2016年頃とされている。つまり来年のフラグシップ級のスマートフォンやサーバーなどに、このCortex-A72が搭載されるというわけだ。
地道な改良で効率を改善している
Cortex-A72は、ハイエンドスマートフォンからサーバーまでの用途を狙う、高性能プロセッサである。具体的にはARMが提供する内部接続機構であるCORELINKと組み合わせ、マルチプロセッサ構成としてGPUやメモリコントローラー、L3キャッシュなどを構成する。

Cortex-A72は、内部接続用のCORELINKと組み合わせることでさまざまな構成が可能になる
CORELINKもシステム規模に応じて複数の製品が用意されており、最大構成では、4コアのクラスタを最大12クラスタ(合計48コア)、メモリコントローラーを4チャンネル搭載可能だ。
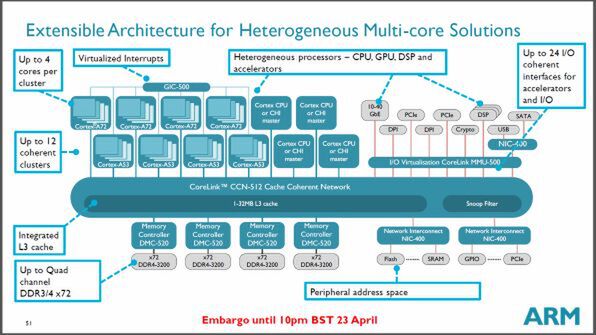
CCN-512を使ったサーバー向けなどの場合、L3キャッシュを持ち、最大24コア、4メモリチャンネルといった構成も可能
Cortex-A72の内部パイプラインは、「命令フェッチ/分岐予測」、「デコード/リネーム」、「ディスパッチ/リタイヤ」、「実行ユニット」から構成されており、実行ユニットが命令を実効したあと、レジスタなどが更新され、「ディスパッチ/リタイヤ」ユニットで終了(リタイヤ)処理が行なわれる。
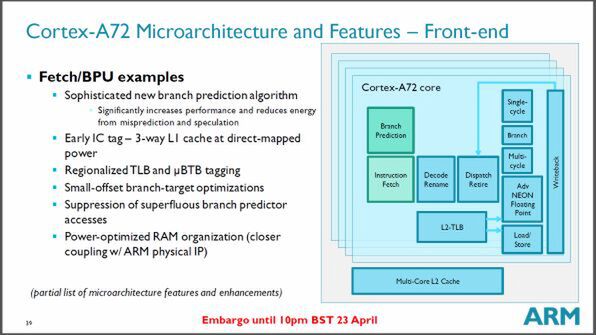
Cortex-A72の内部パイプライン
命令フェッチは、命令を読み出し、後の処理に必要となるタグを命令に付け置くなどの処理を行なう。またここで、分岐命令に関しては、条件分岐が成立するかどうかを予測する。条件付きの分岐命令では、条件が成立するかどうかで、次に実行される命令が違ってくる。
命令の実行順序をかえて処理を行うアウトオブーダー実行では、分岐命令の条件がどうなるかを予測して予測した「次の命令」を実行することで、実行を止めないようにしている。ちなみに予測が間違った場合には実行した命令を無効として、別の命令の実行に切り替える。なお、Cortex-A72では、分岐予測を短い範囲の分岐に最適化しているという。多くの場合、飛び先が比較的近くにある分岐命令は、プログラムの繰り返し(ループ)の一部であり、ここを高速化することで、処理性能を上げることができる。
Cortex-A72では、次の「デコード/リネーム」ステージで、AArch32またはAArch64命令をμOPSという内部的な命令に変換する。このような内部命令セットを使うことで、これ以降の処理は、CPUの動作モードや命令の種類にかかわらず同じ仕組みで処理できるようになる。また、複雑な命令に関しては、複数のμOPSに分割することで、後続の実行ユニットなどを単純化できるというメリットもある。
リネームは、同じレジスタを使っているが、お互いに無関係(同じデータを処理しない)な命令の順番を変えて並列に実行するような場合、物理的には違うレジスタを割り当ててデータを混同しないようにする仕組みだ。
命令が指定しているレジスタ(論理レジスタ)を、論理レジスタよりも多く用意された物理レジスタに書き換えて処理を行なわせる。並列に実行される同じ論理レジスタを使う命令でも、違う物理レジスタを割り当てることで、それぞれを独立して実行できる。こうして演算結果が格納された物理レジスタは、リタイア処理などであとから論理レジスタに対応させ、その時点の正しいレジスタ値として利用できる。「ディスパッチ/リタイア」では、後続の実行ユニットに命令を処理させる。ここでは、最大5命令を同時に発行できるようになった。従来のCortex-A57では3命令だった。
次の実行ユニットは大きく5つある。それは、「シングルサイクル」「分岐」「マルチサイクル(複数サイクル)」「浮動小数点/SIMD演算」「ロードストア処理」だ。「シングルサイクル」および「浮動小数点/SIMD」、「ロードストア」は、それぞれ命令を受け入れるポートが2つあり、2つの命令を並行して処理することが可能だ。
この命令実行ユニットも、高速化されており、従来よりも短いサイクルで命令を実行できるようになった。たとえば、CRCを計算する命令では、Cortex-A57では3サイクルを要していたが、Cortex-A72は、1サイクルで実行が可能になった。また、SIMD演算や浮動小数点演算の積和演算やデータ形式を変換する命令も処理サイクルが短縮されている。また、整数、浮動小数点ともに割り算のアルゴリズムが変更され、処理サイクルが半分になっているという。
ロードストアユニットも2ポートあるが、ロードとストアで各1ポートとなっている。ここは、メモリへの読み書き(ロードとストア)処理を行う部分で、アクセス先のアドレスを計算したり、具体的なメモリアクセス(またはキャッシュアクセス)を行なう。各1ポートになっているため、ロードとストア処理は並行してできる。
また、この部分では、命令で指定されている仮想アドレスを物理アドレスに変換してアクセスを行う必要がある。このためには、MMUのアドレス変換機構を動かさねばならない。これにはある程度の時間を要するが、Cortex-A72ではこの部分を高速化した。
一般に1回アドレス変換を行なうと仮想アドレスと物理アドレスの対応関係をTLB(Translation Look-ahead Buffer)と呼ばれる内部レジスタに記憶して、同じアドレスに対する変換処理が繰り返されるのを防ぐ。このTLBの検索(命令の仮想アドレスを元にすでに変換結果があるかどうかを検索する)も高速化されているようだ。
第1世代のARMv8プロセッサであるCortex-A57は、最初の実装でもあり、あまり性能が出ないといわれていた。その点、Cortex-A72は、実行効率を改善し、ある程度の高速化を達成しているようだ。