名前のタイプを識別する
「言語学的なタグを付ける」というNSLinguisticTaggerの使い方は、かなり直感的でわかりやすいものです。まず、そのクラスのオブジェクトを作成し、そこにプロパティとして解析したいテキストを設定するだけで、準備完了です。あとは若干のオプションを指定しながら、テキストの中の該当する語とタグのペアを順次取り出していくことができます。
最初の例は、テキストに含まれる名前のタイプを判別するものです。この場合は、タガーオブジェクトを作成する際に、タグ付けのスキームとして「.nameType」を指定しています。
そこに「Hi, My name is John Smith. I'm from New York. I'm with ASCII corp.」という適当な英文を設定して、enumerateTagsメソッドを使って名前とタグを取り出しています。文章の中に含まれる単語を先頭から順次取り出すために、結果を列挙するSwift独特の構文を使っています。

現在のiOSの自然言語処理の中核となるのは、「言語学的なタグを付けるもの」という名前のNSLinguisticTaggerクラスです。そのオブジェクトを作る際に、名前のタイプを識別するNSLinguisticTagScheme.nameTypeを指定すると、文に含まれる名前の種類のタグを付けることができます
結果は、名前とそのタイプがペアで表示されるように、文字列の配列として評価し、プレイグラウンドのデバッグ機能を使って表示して確かめました。

結果をプレイグラウンドのデバッグ機能で確認すると、適当に与えた英文に含まれる、PersonalName(人名)、PlaceName(地名)、OrganizationName(組織名)を識別していることがわかります
これによると「John Smith」が人名、「New York」が地名、「ASCII」が組織の名前だと判定しています。これは、なかなか優れた結果ではないでしょうか。特に「ASCII」は、元来は組織の名前ではなく規格の名前ですが、ここでは英語の構文を理解して組織名としているのです。
文章を単語に分解する
次に示す例は、むしろ最初の例よりも単純かもしれません。分析する文章を、ただ単語に分解するというものです。タグ付けのスキームとして「.tokenType」を指定していますが、タグは利用せず、切り出された単語だけを表示しています。

NSLinguisticTaggerクラスのオブジェクトを作る際に、NSLinguisticTagScheme.tokenTypeのスキームを指定すると文を単語に分解することができます。結果はenumerateTagsメソッドの中で、分解された単語を順にwordに代入しています
この結果も、プレイグラウンドのデバッグ機能を使って表示してみます。

結果は、やはりプレイグラウンドのデバッグ機能で確認しましょう。上の例とは異なり、オプションとして.joinNamesを指定していないので、2語からなる名前もそれぞれ別々の単語として認識されています
このように結果をリスト表示するには、いったん「ビューアを追加」して、そのビューア場で「リスト」を選んでからビューアを「削除」します。その後、再び右端の「xx回」の部分をタップすると、その場でリスト表示できるようになります。
英文を品詞に分解する
次に示すのは、機能としては今回の最終的な目的である品詞分解です。この場合、タグ付けのスキームとして「.lexicalClass」つまり「品詞」を指定しています。そうすることで、タグとして名詞(Noun)、動詞(Verb)、形容詞(Adjective)などのような、品詞の種類が出力されます。それを、分解された単語とペアで表示するため、やはり文字列の配列として置いてあります。

タグ付けのスキームとしてNSLinguisticTagScheme.lexicalClassを指定すると、文を単語に分解して単語ごとの品詞をタグとして付けることができます。品詞はLexical Categoryと呼ぶのが一般的ですが、Lexical Classと言う場合もあります。このクラスのスキーム名としては後者使われています
プログラムの形は、結果のタグを利用している点を除けば、上の例とほとんど同じです。結果は、やはりプレイグラウンドのデバッグ機能で確認しましょう。

このプログラムでは、切り出された単語とそのタグのペアを1つの文字列の配列の要素として置いているので、プレイグラウンドのデバッグ機能を使って容易に対応を確認することができます
品詞分解機能をアプリとして動作させる
ここまでのプログラムでは、プログラムに埋め込んだ固定の文字列でしか試せませんでした。プレイグラウンドで実験的なプログラムを動かすだけなら、それでも構いません。しかし、いろいろな文を分析させて結果を確かめたい場合には、ちょっと不便です。そこで、ユーザーが文を入力できるテキストフィールドを備えた簡単なアプリにまとめてみることにします。
アプリのユーザーがインターフェースとしては、これまでに何度も登場したような一般的なものです。ビューコントローラーのビューの上に、テキスト入力するUITextField、分析を実行するUIButton、結果を表示するUITextViewを配置します。ボタンをタップすると、同じビューコントローラー内のtokenizeというメソッドが呼ばれるように設定しています。

品詞分解の機能を簡単なアプリとして実現するために、UIKitをインポートしてLTViewControllerクラスを作ります。そのビューの上に、元の文を入力するテキストフィールドと分析を開始するボタン、結果を表示するテキストビューを配置します
そのtokenizeメソッドの中では、上の例で示したようなNSLinguisticTaggerクラスによる品詞分解のプログラムを実行します。結果は、単語と品詞の名前をタブで区切り、1行ごとに改行を入れて、文字列型のresultという変数に加えていきます。

ユーザーがボタンをタップすると呼ばれるように設定したtokenizeメソッドでは、上の例で示した品詞分解のプログラムをほとんどそのまま実行します。ただし、結果は単語と品詞のペアをタブと「: 」で区切った文字列として、ペアごとに改行も加えて連結していきます
その結果はテキストビューに表示するわけですが、その際には、タブ記号によって単語と品詞がはっきり別れ、かつ単語の長さによらず品詞の名前がそろって表示されるようにしたいところです。そのため、テキストビューに表示するテキストの段落スタイルのタブの位置をカスタマイズしています。結果のテキストには、そのタブを設定して段落スタイルと、大きめのフォント(20ポイントのシステムフォント)を属性と付加し、テキストビューのattributedTextのプロパティに代入しています。

タブによって、単語と品詞の間を十分な距離だけ離して配置するために、170ポイントという大きめの幅のタブ1つだけを含んだ段落スタイルを作成し、結果の文字列の属性として付加しています。結果の文字列には、ほかに20ポイントという大きめのフォントも別の属性として付加します
このプログラムを動かし、最上部のテキストフィールドに適当な文を入力して「分析!」ボタンをタップすると、結果が下のテキストビューに表示されます。
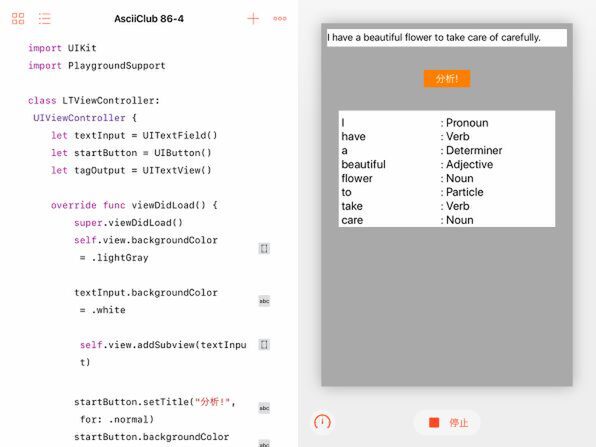
いちばん上に配置したテキストフィールドに分析したい文を入力してから「分析!」ボタンをタップすると、文を品詞分解した結果が、単語と品詞のペアとしてきれいに整形されて表示されます
テキストビューなので、文が長くて結果の行数が多いときは、下の方の行はパンやフリックのジェスチャーによってスクロールさせて表示できます。
次回の予定
今回は、機械学習の成果としても、自然言語の品詞分解という比較的地味な機能を試してみました。このNSLinguisticTaggerは、英語以外の複数の言語に対応しています。日本語にもまったく対応していないわけではないのですが、文法構造などがまったく異なるためか、現状では品詞分解は正しくできないようです。次回もCore MLの続きとなりますが、もう少し視覚的にも楽しめる機能を実装していきたいと考えています。