Visionが認識した単語や文字を個別の画像として切り出す
今回認識した結果は、単語にせよ文字にせよすべて長方形となるので、それぞれを独立した画像として切り出すのも簡単です。コアグラフィックス画像(CGImage)のcroppingメソッドによって簡単に切り出すことができます。ただし、元の画像は一般的なUIImageなので、それをいったんCGImageに変換し、切り取った結果を再びUIImageに戻して表示に備えます。コアグラフィックスを利用することで、画像の上に図形を描くために必要だったイメージコンテキストも不要になります。

認識した単語と文字の枠を描く代わりに、認識した長方形を使って画像を切り取り、元の画像とは独立した別の画像として取り出してみます。元の画像(UIImage)をCGImageに変換してからcroppingメソッドを使っています
また、UIImageとCGImageとでは、座標系が異なるので、切り取る長方形を指定する場合に注意する必要があります。UIImageは左上、CGImageは左下の角がそれぞれ原点です。そこで、y座標をひっくり返した形にすることと、長方形の高さと原点の位置の違いを考慮して新たなy座標を求める必要があります。単語単位で認識し、 その中から文字を取り出すというパターンは、前の例と同じです。

まずは単語単位で切り取り、さらにその中の文字単位で切り取っています。切り取ると言っても、カットではなくコピーなので、元の画像は変化しません
この例では、切り出した結果をUIImageとして定数に保存しているので、やはりデバッグ機能を使って確認することができます。

プレイグラウンドのデバッグ機能を使って、最後に切り取った画像を確認することができます。この例では「AMD新型の実力がわかった」という文を、1つの「単語」と認識しているのです
ただし、forループで繰り返して切り出した結果の画像は、このような方法では最後の1つしか確認できません。結果の「ビューア」でリスト表示を選んでも、画像はリスト表示できないのです。
そこで、プレイグラウンドのステップ実行機能を使えば、途中経過も確認できます。普段の「コードを実行」ボタンの左にあるタイマーのようなアイコンをタップして「コードをステップ実行」を選びましょう。表示したい画像オブジェクトを作成している行の右端をタップして内容を表示しておけば、プログラムの動作に従って、切り取った画像が更新されていきます。

プレイグラウンドのステップ実行機能を使えば、個々の文字を順番に切り出してくる様子を、切り出した結果の画像で確認することができます
切り出した文字をコレクションビューに一覧表示する
せっかく文字単位で画像が切り出せるようになったので、その一覧表を表示してみることにしましょう。そのためには、以前に使ったコレクションビューを利用するのが良さそうです。もちろんテーブルビューを使ってもいいのですが、それだと無駄なスペースが大きくなってしまいます。コレクションビューについては、82〜85回めあたりで取り上げているので、そちらも参照してください。
コレクションビューを使って画像を表示する部分は、以前のプログラムとまったく同じです。違うのは、以前はあらかじめ用意しておいた画像の配列から表示していたのに対して、今回はVisionで認識した文字を切り出した画像をいったん配列に格納し、そこから表示していることです。
簡単に言えば、以前のコレクションビューを表示するビューコントローラーのviewDidLoadメソッドの中に、今回のVisionによる文字認識と切り出しのプログラムを入れ込むような形になります。
クラスは2つ定義します。1つめはカスタムなセルを定義するImageCellで、これは以前のものとまったく同じです。

せっかく切り出した画像が消えてしまわないよう、コレクションビューに一覧として表示して見ることにしましょう。以前の例を参考に、まずImageCellクラスを定義します
コレクションビュー自体を表示するCollectionViewControllerクラスでは、まず切り出した画像を格納するcImagesというUIImageの配列の変数を用意しています。

コレクションビューの本体となるCollectionViewControllerクラスでは、切り出した画像を保存しておくために、UIImageの配列となる変数、cImageを定義しています
すでに述べたように、以前の例のviewDidLoadメソッドの中を大幅に拡張して、上で示した認識と切り出しのプログラムをほとんどそのまま入れています。ただし、今回は単語の切り出しはやめて、その中の文字だけを画像として切り出すことにしました。
文字を含まない画像を認識させようとした場合、あるいは文字が1つも認識できなかった場合に備えて、認識結果にcharacterBoxesが含まれているかをチェックしています。含まれて入れば、1文字ずつ取り出し、そのUIImageオブジェクトを上で用意したcImages配列の要素として加えています。

ここでは、単語の切り出しはやめて文字のみを切り出し、結果を表示しやすいUIImageに戻してから、順に配列に保存しています
コレクションビューに関するその他の部分は以前に示したプログラムと全く同じなので、説明は省きます。

コレクションビュー自体の表示に関する部分は、以前のコレクションビューのプログラムと基本的に同じです。セルに表示する画像としては、切り出した画像を保存した配列から、indexPath.rowをインデックスとするものを取り出して設定しています
このプログラムを実行すると、1つの画像の中の認識したすべての文字をコレクションビューに表示します。
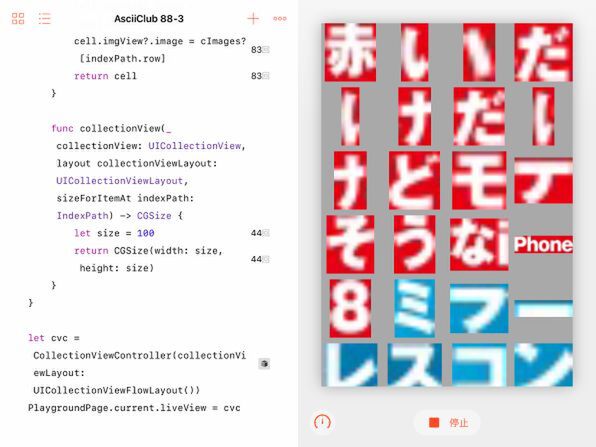
週アスの表紙画像から認識できた文字を、1つずつ画像として表示しています。ひらがなの「い」や「け」は、左右に分かれて2文字として認識されてしまっています。日本語の文字の認識はあまり得意ではないようです
これを見ると、2つのパーツから構成されているひらがなを2文字のように認識したり、カタカナの一部が欠落したり、ひらがなとアルファベットの連続した部分を1文字として認識してしまったりしていることがわかります。やはり、日本語の文字については、Visionが利用している機械学習の成果が、まだ十分ではないということでしょう。
一方、英文だけを含む画像を認識させてみると、手書き風の文字も含めて背景がプレーンであればほぼ100%の認識率になります。

背景が白ということもありますが、英文に含まれる文字の認識率はかなり高く、特に不明瞭な点がなければほとんど100%となるでしょう
このあたりのギャップが埋まるまでには、まだ時間がかかりそうです。
次回の予定
今回は、Visionフレームワークを使って、画像に含まれる単語や文字を認識させてみました。文字の領域を画像として認識できても、そこから先、文字の意味、つまりそれが何という文字かはどうやって知ることができるのか、と疑問に思った人もいるでしょう。実はVisionは、今のところそこまでの機能は含んでいません。いわゆるOCR的な機能は、適切なモデルを用意してCore MLを直接使うことで実現できるはずですが、それについては別の機会に譲ります。次回も、あと1回だけVisionフレームワークを取り上げ、また別の機能を探求してみるつもりです。