いつでも彼氏としりとりができるbot
日中はLINEすら返してくれない彼氏に代わって、私としりとりをしてくれるbotは以下のような順番で作っていきたいと思います。
1. 彼氏とのLINEのトーク履歴を取得する。
2. 私のメッセージデータは除き、彼氏のメッセージデータから名詞を抽出する。
3. 抽出した名詞をひらがなに変換し、しりとりの語彙にする。
4. 彼氏の語彙リストをもとに、プログラミング言語「Python」でしりとりをする。
5. グーグルが提供する「Google App Engine(GAE)」を利用してLINE Botから使えるようにする。
前編では1~3、後編では4〜5について紹介します。
開発環境は以下のとおりです。
・macOS Catalina 10.15.3
・Python 3.7.1
1.彼氏とのLINEのトーク履歴を取得する

まずは、彼氏とのトーク履歴をダウンロードします。
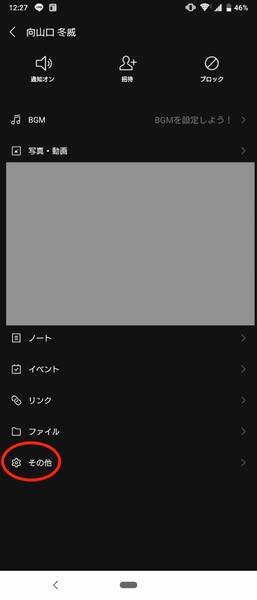
トーク画面の右上にある「≡」をタップし、1番下にある「その他」を選択
履歴をダウンロードしたい相手とのトーク画面を開き、右上の「≡」をタップし、1番下にある「その他」を選択します。

「トーク履歴を送信」をタップ
「トーク履歴を送信」をタップすると、メールやLINE、Bluetoothなどでトーク履歴をテキストファイル(.txt)で共有できます。
以下のように(ちょっと汚いですが……)テキストデータの整形もPythonで実施しましたが、Microsoft ExcelやテキストエディタなどでもOKです。
#LINEのトーク履歴のテキストファイルを読み込む
with open('ファイル名.txt') as f:
#改行、空白を削除
lines = [s.replace('\n','').replace('\t','_').replace('\u3000','') for s in f.readlines()]
lines = lines[3:] # 先頭の3行を削除
#彼氏のトーク履歴リスト
kareshi_text = []
#西暦を含む行を削除
lines = [l for l in lines if ('2016' not in l) and ('2017' not in l) and ('2018' not in l) and ('2019' not in l) and ('2020' not in l)]
#文頭に時間以外がきてしまっている行を削除
lines = [l for l in lines if (':' in l) and ('_' in l)]
#彼氏の発言のみを抽出
for line in lines:
#時間を削除
line = line[6:]
#彼氏の名前に一致するメッセージをリストに追加
if "彼氏の名前" in line:
kareshi_text.append(line[7:])
#テキストファイルに出力
str_ = '\n'.join(kareshi_text)
with open('ファイル名.txt', 'w') as f:
f.write(str_)
今回はLINEのトーク履歴を利用しましたが、文章データであればなんでも大丈夫なので、ぜひ自分の好きな小説や歌詞、その他SNSのデータなどでも試してみてください!
ちなみに、せっかくデータを取得したので、彼氏から送られてきたメッセージと私が送ったメッセージをそれぞれ数えてみたら、彼氏からが57564通、私からが64234通でした。
もうほんとにどうでもいいことなんだけど、2016年8月31日から2020年3月6日までの彼氏とのトーク履歴数えてみたら、
— らんらん メンヘラテクノロジー (@pascarrr) April 22, 2020
彼氏→私:57564通
私→彼氏:64234通
ってかんじで、思っていたより、私から彼氏に送ったメッセージのほうが多かったので、もっと彼氏からメッセージ送ってもらいたいなーと思った pic.twitter.com/ceCgagpjI1
今回は2016年8月31日から2020年3月6日、つまり1248日間のトーク履歴をダウンロードしていています。平均すると、彼氏は1日46.13通、私は51.47通のメッセージを送っている計算になります。
私の方が多いので、もう少し彼氏からもメッセージを送ってもらえたら、うれしいなと思いました(話が逸れてしまい、すみません)。
2.彼氏からのメッセージデータから名詞を抽出する
テキストデータを形態素解析し、名詞を抽出します。ここでは、形態素解析エンジン「MeCab」を使います。
MeCabはオープンソースの形態素解析エンジンで、奈良先端科学技術大学院大学出身、現GoogleソフトウェアエンジニアでGoogle 日本語入力開発者の一人である工藤拓によって開発されている。名称は開発者の好物「和布蕪(めかぶ)」から取られた。
(Wikipediaより引用)
MeCabと辞書のインストールは、パッケージ管理システム「Homebrew」を使って以下のように実施します。
$ brew install mecab $ brew install mecab-ipadic
以下で多数のウェブ上の新語が追加されたMeCab用のシステム辞書のmecab-ipadic-NEologdをインストールできます。
$ brew install git curl xz
$ git clone --depth 1 git@github.com:neologd/mecab-ipadic-neologd.git
$ cd mecab-ipadic-neologd
$ ./bin/install-mecab-ipadic-neologd -n
次に、Python3からMeCabを使えるようにするためのモジュールもインストールします。
$ brew install swig
$ pip install mecab-python3
続いて、このMeCabを使って形態素解析と名詞を抽出します。まず、試しに「私は彼氏にかまってもらえなくて寂しいです」という文を形態素解析してみます。
import MeCab
import sys
import re
from collections import Counter
# 単語分割
mecab = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
parse = mecab.parse('私は彼氏にかまってもらえなくて寂しいです')
print(parse)
実行すると、以下のような出力結果が得られます。
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
彼氏 名詞,一般,*,*,*,*,彼氏,カレシ,カレシ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
かまっ 動詞,自立,*,*,五段・ワ行促音便,連用タ接続,かまう,カマッ,カマッ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
もらえ 動詞,非自立,*,*,一段,未然形,もらえる,モラエ,モラエ
なく 助動詞,*,*,*,特殊・ナイ,連用テ接続,ない,ナク,ナク
て 助詞,接続助詞,*,*,*,*,て,テ,テ
寂しい 形容詞,自立,*,*,形容詞・イ段,基本形,寂しい,サビシイ,サビシイ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
EOS
ここに、さきほどLINEのトーク履歴から取得したテキストデータを入れ、MeCabの出力結果から品詞が「名詞」かつ、品詞再分類が「一般」の単語を絞り込み、カタカナ表現の部分を取得します。
#彼氏からのメッセージを保存したテキストファイルを読み込む
with open('ファイル名.txt') as f:
text = f.read()
# 単語分割
mecab = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
parse = mecab.parse(text)
lines = parse.split('\n')
items = (re.split('[\t,]', line) for line in lines)
# 名詞をリストに格納
words_list = []
for item in items:
if (item[0] not in ('EOS', '', 't', 'ー') and item[1] == '名詞' and item[2] == '一般'):
for item in items:
words_list.append(item[-1])
以下が名詞リストの中身のイメージです。
['デカ', 'デンシャ', 'ゴハン', 'オナカ', 'ツーシン', 'イゲン', 'アイ', 'ギョーザ', '*', 'ラン', 'ラン', 'ウム', 'ウム', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ', 'スタンプ',
・・・
, 'トーミ', 'アソン', 'アト', '*', '*', 'マッシュポテト', 'ツギ', 'オムライス', 'ランキング', 'オムライス', 'オナカ', 'ウチ', 'ゴハン', 'ラン', 'ウチ', 'ジムショ', 'ヒトリ', 'オシ', '*', 'カンガエ', 'コンビニ', 'コンビニ']
3.抽出した名詞をひらがなに変換ものをしりとりの語彙にする
MeCabで作成した名詞リストの中身をしりとりで使えるように、すべてひらがな表記で2文字以上に加工していきます。
まずは、以下で名詞リスト内で重複している単語を削除します。
#重複している単語を削除
words = [w for w in set(words_list) if words_list.count(w) > 1]
ひらがなの変換は「jaconv(Japanese Converter)」を使います。
以下のように「pip」でインストールできます。
$ pip install jaconv
正規表現を使ってカタカナの単語を削除してから、1文字以下の単語も削除し、ひらがなに変換していきます。そして、最後に「ん」で終わる単語を削除します。
import jaconv
import re
#カタカナの単語を検索するための正規表現
katakana = re.compile('[ァ-ン]+')
words_kana = []
for word in words:
#カタカナの単語以外を削除
if katakana.search(word):
#1文字以下の単語を削除
if len(word) >= 2:
#カタカナの単語をひらがなに変換
words_kana.append(jaconv.kata2hira(word))
#「ん」で終わらない単語のみを抽出
not_n_words = [s for s in words_kana if not s.endswith('ん')]
実行後の名詞リストは以下のようになりました。
['きゃく', 'ふくろう', 'しゅー', 'ざんだか', 'もくてき', 'かいしゃ', 'くせ', 'ねつ', 'もーしこみ', 'ばんぐみ', 'すと', 'おかね', 'じんじ', 'ぐふ', 'すにーかー', 'おひる', 'せんたくし', 'にす', 'しにたい', 'かぞく', 'がす', 'ほにゅーるい', 'どんき', 'ありーな', 'ふくそー', 'たばこ', 'あこがれ', 'じさ', 'ぱすぽーと', 'かり', 'たな', 'えきまえ', 'じか', 'たは', 'せつ', 'さつ', 'かめ', 'ひょー', 'ごぼー', 'しゅくー', 'どりんく', 'しはつ', 'やじ', 'てあし', 'だる', 'すくらんぶる', 'ぱちんこ', 'じたい', 'らすと', 'ぴざ', 'てりや', 'ぶき', 'いね', 'もうふ', 'ひーる', 'ぎょーむ', 'きぼ',
・・・
,'ぱすわーど', 'たーげっと', 'まど', 'どーし', 'やー', 'えびす', 'ばす', 'とびこみ', 'だいし', 'ものがたり', 'しすてむ', 'すきー', 'やんちゃ', 'けいひ', 'あるぱか', 'ぺーす', 'しか', 'おりたたみ', 'りすと', 'げんじつ', 'ぞう', 'たて', 'まにあ', 'さーじ', 'のど', 'じんじゃ', 'しばいぬ', 'だいどころ', 'あくま', 'ふり', 'くさ', 'きんく', 'めっせーじ', 'めでぃあ', 'ちゃいろ', 'くいな', 'とらんくす', 'ぐるーぷ', 'しゃてい', 'おとな', 'しゃめい', 'がき', 'じっしつ', 'りすく', 'おーなー', 'にっきゅー', 'つごー', 'まちあわせ', 'なか', 'こーがくれき', 'かけ', 'るーむ', 'さいしゅー', 'やすみ', 'おいえ', 'やるき', 'どーれつ', 'ぎんこー', 'めやす', 'こすと', 'みどり', 'しょくば', 'じょーし', 'そざい', 'じんるい', 'つけ', 'きょーしつ', 'へり', 'ぜんがく', 'ながでんわ', 'だして', 'えさ']
細かく見ていくと、「これは名詞なのか……?」というものもたまにありますが、彼氏が使った単語だと思えばまったく気になりません!
ちなみに、今回作成したしりとり用の名詞リストにある単語数は全部で1665個となりました。
後編では、この1665個のボキャブラリーをもつ彼氏風しりとりbotを完成させていきたいと思います。
高桑蘭佳(たかくわらんか)

1994年生まれ。石川県出身。東京工業大学大学院環境社会理工学院修士課程在学中。2018年8月にメンヘラテクノロジーを設立。彼氏を束縛したくて起業した大学院生として「アウト×デラックス」(フジテレビ系列)や、「指原莉乃&ブラマヨの恋するサイテー男総選挙」(AbemaTV)などに出演。